Tính phụ thuộc trong ngôn ngữ
Các khái niệm trong một câu thường mang tính phụ thuộc và bổ trợ lẫn nhau. Ví dụ như tính từ bổ nghĩa cho danh từ, trạng từ bổ nghĩa cho động từ, trạng từ cũng có thể bổ nghĩa cho tính từ, .... Những thành phần này tạo nên mức độ chi tiết cho câu và giúp xác định chính xác đối tượng, tránh nhập nhằn. Ví dụ cho câu:
S = "A(Det) brown(Adj) dog(N) rapidly(Adv) chases(V) a(N) small(adj) black(adj) cat(V)."
Trong câu trên có nhiều tính từ mô tả như "brown", "small", "black" bổ sung thông tin thêm cho các đối tượng "dog", "cat". Trạng từ "rapidly" bổ sung thêm thông tin cho hành động "chases". Các đối tượng "dog", "cat" cũng bổ sung thông tin cho hành động "chases", làm rõ nghĩa đâu là đối tượng thực hiện hành động và đâu là đối tượng bị tác động. Có thể thấy tính phụ thuộc trong câu mang tính phân tầng, từ này bổ nghĩa cho từ khác và từ khác bổ nghĩa cho từ khác nữa để hợp thành thông tin chung của cả câu.
Biểu diễn thành phần phụ thuộc
Dựa trên tính chất phân tầng như vậy, ta thấy cấu trúc cây là cấu trúc phù hợp cho biểu diễn tính phụ thuộc trong một câu. Cây phụ thuộc của một câu thể hiện mối quan hệ bổ nghĩa trong câu đó, các nút con bổ sung thông tin cho nút cha. Ví dụ cây phụ thuộc của câu "A brown dog rapidly chases a small black cat." như sau:
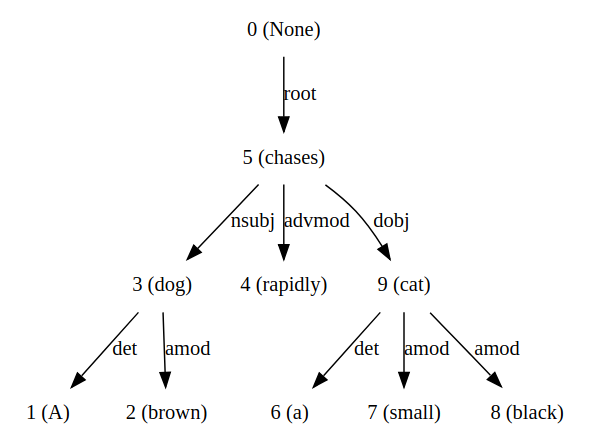
Từ ví dụ trên, ta có thể thấy đặc tính của cây phụ thuộc như sau:
- Cây phụ thuộc bắt đầu từ một nút đặc biệt ROOT làm nút gốc
- Mỗi thành phần chỉ có duy nhất một nút cha, hay nói cách khác mỗi thành phần chỉ bổ nghĩa cho một thành phần khác nhưng một thành phần có thể được nhiều thành phần khác bổ nghĩa cho nó
- Là một đồ thị có hướng không chu trình (đặc tính này khá rõ ràng do cấu trúc cây nhưng quan trọng nếu biểu diễn cây như một đồ thị)
- Các quan hệ phụ thuộc không được cắt nhau (non-crossing).
Đặc biệt, tính chất không được cắt nhau khá quan trọng. Tính chất này là do đặc điểm của ngôn ngữ là các thành phần phụ thuộc thường đứng gần nhau và tạo thành một cụm đầy đủ ngữ nghĩa. Việc xuất hiện "crossing" tức là một cụm liên tục bị chen vào một thành phần không liên quan đến cụm đó. Ví dụ với hai cây phụ thuộc thu gọn sau đây:
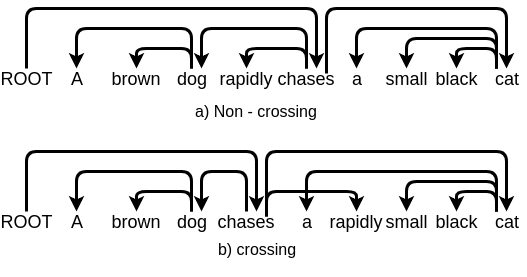
Ở đây, "a small black cat" là một cụm đầy đủ ngữ nghĩa, việc chen từ "rapidly" vốn là từ bổ nghĩa cho động từ "chases" vào cụm đầy đủ này sẽ gây ra crossing. Đặc thù về ngữ pháp và tính dễ đọc của ngôn ngữ đảm bảo cho việc các từ bổ sung ngữ nghĩa cho nhau nên đứng gần nhau và có thể được gom thành một cụm thống nhất. Một câu không đảm bảo ngữ pháp và tính dễ đọc sẽ có thể gây ra crossing khi phân tích cây phụ thuộc.
Phân tích thành phần phụ thuộc
Bài toán đặt ra chính là làm sao để có thể phát sinh cây phụ thuộc với một câu đầu vào cho trước. Có nhiều phương pháp đã được đề xuất để giải bài toán này. Trong bài viết này sẽ giới thiệu hai phương pháp theo hướng dựa trên data (data driven).
Phân tích dựa trên phương pháp chuyển dịch - transition base
Ý tưởng chính của phương pháp chuyển dịch là xem quá trình sinh cây như sự chuyển dịch trong một máy trạng thái. Từ trạng thái băt đầu, dựa trên các luật chuyển dịch để đưa đến một trạng thái mới và cuối cùng đưa đến trạng thái cuối cùng là hoàn thành việc sinh cây. Một hệ thống chuyển dịch gồm các thành phần sau:
- Bộ 3 Stack, Buffer, Arc (S, B, A): dùng để biểu diễn một trạng thái. Trong đó Stack dùng để chứa các từ đã được xét đến. Buffer dùng để chứa các từ chưa được xét đến. Arc dùng để chứa các mối quan hệ phụ thuộc được sinh ra trong quá trình chuyển dịch.
- Trạng thái khởi đầu ([], [w1, w2, w3, ...], []): được khởi tạo với Stack và Arc trống, Buffer sẽ chứa câu cần phân tích đã được chia thành các từ cụ thể (tokens).
- Trạng thái kết thúc (S, [], A): Kết thúc khi tất cả các từ trong Buffer và Stack đã được xử lý.
- Các luật chuyển dịch trạng thái: dựa trên trạng thái hiện tại, các luật chuyển dịch sẽ quyết định trạng thái mới cùng với các mối quan hệ phụ thuộc được sinh ra trong quá trình chuyển dịch.
Các thao tác chuyển dịch bao gồm:
- Shift : di chuyển từ đầu tiên trong Buffer vào trong Stack (S, w|B, A) -> (S|w, B, A).
- Left-arc: kiểm tra quan hệ hai từ trong top của Stack, lấy từ "bên trái" (bên dưới) ra khỏi Stack và thêm quan hệ vào trong Arc (S|w1|w2, B, A) -> (S|w2, B, A + {w1 <- w2})
- Right-arc: tương tự như left-arc, kiểm tra quan hện hai từ trong top của stack, lấy từ "bên phải" (bên trên) ra khỏi Stack và thêm quan hệ vào trong Arc (S|w1|w2, B, A) -> (S|w1, B, A + {w1 -> w2})
Sau một loạt các phép chuyển đổi, lần lượt các từ trong Buffer sẽ chuyển dần qua Stack thông qua thao tác Shift. Các từ trong Stack sẽ được xử lý để xác định mối quan hệ và thêm vào Arc dựa trên các thao tác left-arc và right-arc. Ví dụ cho quá trình sinh cây quan hệ cho câu "A dog chases a cat." như sau:
| Action | Stack | Buffer | Arc |
| [ROOT] | [A, dog, chases, a, cat] | A | |
| (1) Shift | [ROOT, A] | [dog, chases, a, cat] | A |
| (2) Shift | [ROOT, A, dog] | [chases, a, cat] | A |
| (3) Left-arc | [ROOT, dog] | [chases, a, cat] | A + {A <- dog} |
| (4) Shift | [ROOT, dog, chases] | [a, cat] | A |
| (5) Left-arc | [ROOT, chases] | [a, cat] | A + {dog <- chases} |
| (6) Shift | [ROOT, chases, a] | [cat] | A |
| (7) Shift | [ROOT, chases, a, cat] | [] | A |
| (8) Left-arc | [ROOT, chases, cat] | [] | A + {a <- cat} |
| (9) Right-arc | [ROOT, chases] | [] | A + {chases -> cat} |
| (10) Right-arc | [ROOT] | [] | A + {ROOT -> chases} |
Dựa vào các quan hệ thu được trong tập Arc, ta có thể xây dựng thành cây phụ thuộc như sau:
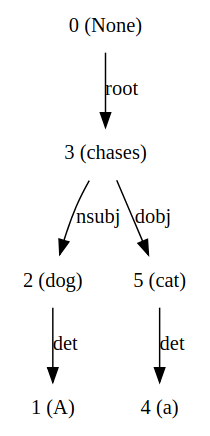
Việc chọn đúng thao tác chuyển dịch vô cùng quan trọng trong việc sinh cây phụ thuộc. Ví dụ như tại bước (6), thay vì thực hiện thao tác Shift, ta thực hiện Right-arc để kết hợp ngay {Root -> chases} sẽ khiến từ "chases" bị bỏ khỏi Stack và không thể dùng để sinh ra các quan hệ phía sau. Nhưng làm thế nào để có thể xác định được khi nào nên dùng thao tác chuyển dịch nào? Một trong các giải pháp chính là sử dụng máy học (Machine Learning) để học một bộ phân lớp nhận vào trạng thái hiện hành (S, B, A) và quyết định thao tác cần thực hiện. Với một bộ ngữ liệu đủ lớn đã được gán sẵn các quan hệ phụ thuộc cũng như các thao tác tương ứng với từng trạng thái, ta có thể xây dựng một mô hình phân lớp để chọn ra thao tác nào cần thực hiện để chuyển dịch từ trạng thái hiện hành sang trạng thái khác. Cốt lõi của phương pháp chuyển dịch này vẫn là huấn luyện một mô hình phân lớp dựa trên dữ liệu nên nó được xếp vào phương pháp data-driven.
Phân tích dựa trên phương pháp đồ thị - graph base
Cách tiếp cận của phương pháp đồ thị dựa trên việc xem cây phụ thuộc như một đồ thị có hướng. Như đã đề cập về thuộc tính của cây phụ thuộc, cây là một đồ thị có hướng không chu trình và mỗi nút trong đồ thị chỉ có duy nhất một nút trỏ đến nó (có duy nhất 1 nút cha, ngoại trừ nút đặc biệt ROOT). Dựa vào các đặc điểm này ta có thể chuyển đổi bài toán trở thành tìm cây khung phù hợp khi cho trước một đồ thị đầy đủ.
Từ câu văn trong ngôn ngữ tự nhiên đã được chia thành các tokens, ta có thể xây dựng một đồ thị đầy đủ có hướng với các đỉnh là các tokens và các cạnh là mối quan hệ phụ thuộc giữa hai tokens. Các cạnh sẽ có trọng số là mức độ tin cậy của mối quan hệ phụ thuộc giữa hai tokens đó.
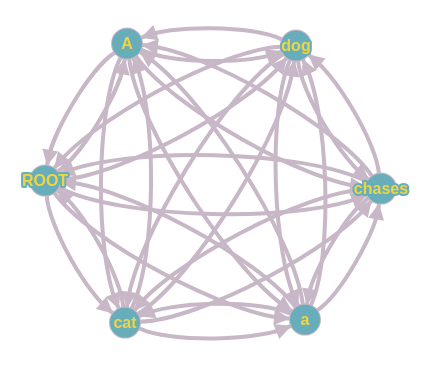
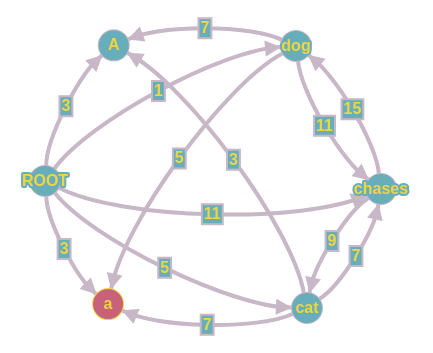
Tuy nhiên, sẽ có những quan hệ phụ thuộc gần như không bao giờ xảy ra (vd như quan hệ từ các tokens trỏ vào ROOT). Ta có thể lượt giản bớt các quan hệ này để đồ thị trở nên đơn giản hơn. Trong ví dụ, trên một số các quan hệ đã được lượt giản để tiện cho việc tính toán. Như vậy ta có một đồ thị có trọng số và cần tìm một cây khung lớn nhất (Maximum Spanning Tree) thỏa các tính chất của một cây phụ thuộc.
Một đặc điểm của cây phụ thuộc chính là mỗi nút đều chỉ có một đầu vào hay chỉ có duy nhất một nút khác trỏ tới nó. Dựa vào đặc điểm này, ta tiến hành chọn các cạnh vào có trọng số cao nhất cho mỗi nút (trừ nút ROOT). Nếu như không có hình thành chu trình thì ta đã có được cây khung thỏa các điều kiện và đó cũng chính là cây phụ thuộc.
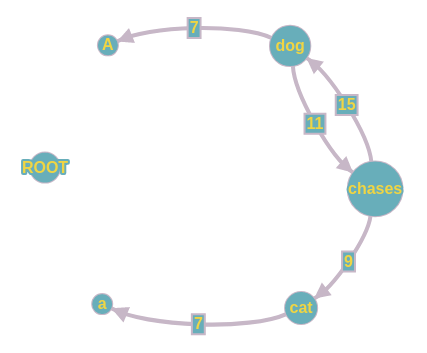
Tuy nhiên trong trường hợp xảy ra chu trình như trong hình trên, ta tạm xem vị trí xảy ra chu trình là một nút và tính lại các giá trị đầu vào và đầu ra cho nút mới này dựa trên các đường đi có thể có. Ví dụ, từ nút ROOT có thể đến nút (dog, chases) thông qua 2 đường (ROOT->dog->chase, ROOT->chases->dog) với trọng số mới là (1 + 11) = 12 và (11 + 15) = 26. Tương tự ta cũng sẽ có đầu vào từ nút cat là (cat->chases->dog) với trọng số là (7 + 15) = 22. Ta tiếp tục tiến hành chọn đầu vào có trọng số cao nhất và có được đường đi duy nhất là (ROOT->chases->dog). Như vậy là ta đã phá chu trình và có được cây khung phù hợp cũng chính là cây phụ thuộc.
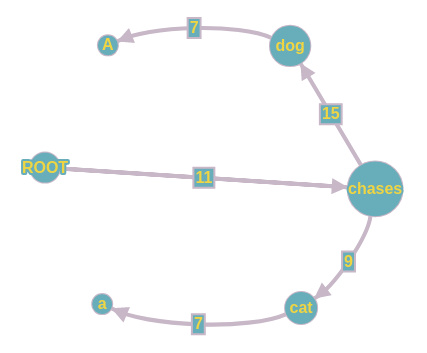
Điểm mấu chốt trong phương pháp này, cũng tương tự như trong phương pháp chuyển dịch, là làm sao đánh trọng số đúng các mối quan hệ phụ thuộc giữa các tokens. Việc đánh giá sai trọng số của các mối quan hệ phụ thuộc sẽ dẫn đến cây khung lớn nhất không tương thích với cây phụ thuộc. Tuy nhiên, tương tự như trong phương pháp chuyển dịch, ta cũng có thể xây dựng một mô hình học để đánh giá mối quan hệ phụ thuộc giữa hai từ (có tính chất thứ tự A->B khác B->A). Trọng số này có thể là tỉ lệ xuất hiện mối quan hệ phụ thuộc này trong các cây phụ thuộc có trong bộ ngữ liệu huấn luyện. Do học dựa trên ngữ liệu nên phương pháp này cũng thuộc vào nhóm data-driven.
Áp dụng cây phụ thuộc
Việc phân tích thành phần phụ thuộc có thể giúp hỗ trợ trong nhiều bài toán. Có thể thấy rằng các cây con trong một cây phụ thuộc là một cụm đầy đủ ngữ nghĩa, ta có thể dùng phương pháp rút trích các cây con để giải quyết bài toán tìm các cụm này (chunking). Cây phụ thuộc cũng có thể dùng làm một tiêu chí đánh giá tính đễ đọc và ngữ pháp của câu văn dựa trên việc kiểm tra crossing trong cây phụ thuộc. Đặc biệt trong một số bài toán trong lĩnh vực trí tuệ nhân tạo như dịch máy (machine translation), trả lời câu hỏi thị giác (visual question answering), mô tả hình ảnh (image captioning), ..., tính chất phụ thuộc có thể được áp dụng. Ví dụ như trong bài toán trả lời câu hỏi, thông tin phụ thuộc có thể giúp tìm kiếm và trả lời nhanh chóng các câu hỏi liên quan đến tính chất phụ thuộc (vd: What color is the dog?). Cây phụ thuộc cũng thể hiện tính chi tiết của câu. Cây càng "cao" thì câu mô tả càng phải chi tiết (vì bổ sung thêm nhiều thông tin phụ thuộc). Ta có thể dùng tính chất này để điều chỉnh mức độ chi tiết cho câu mô tả của một hình ảnh.
Bài viết tham khảo từ các nguồn
Stanford Natural Language Processing Course
http://www.cs.umd.edu/class/fall2017/cmsc723/slides/slides_13.pdf