Biểu diễn cú pháp cho văn bản
Văn phạm trong ngôn ngữ tự nhiên là quy tắc chủ yếu trong cấu trúc ngôn ngữ. Các từ trong một câu đuợc ghép nối với nhau dựa trên văn phạm để hình thành nên câu có nghĩa và thông qua đó thể hiện vai trò của từ trong ngữ nghĩa của câu. Trong đa số ngôn ngữ, câu có thể chia làm hai phần chính là chủ ngữ và vị ngữ. Trong chủ ngữ lại có thể bao gồm danh từ, cụm danh từ, đại từ, mệnh đề, ... và trong vị ngữ có thể có động từ chính, trạng từ, bổ túc từ, .... Xét nhỏ hơn nữa có thể chia tiếp cụm danh từ, mệnh đề thành các thành phần nhỏ hơn và cho đến khi chỉ còn lại từ và từ loại của nó (không thể chia cú pháp đuợc nữa). Dựa vào cách phân tích cú pháp trong ngôn ngữ tự nhiên này ta nhận thấy cấu trúc cây phù hợp để biểu diễn cú pháp văn phạm cho một câu.
S = "a(Det) quick(Adj) brown(Adj) fox(N) jumps(V) over(P) the(Det) lazy(Adj) dog(N)"
a quick brown fox jumps over the lazy dogDựa vào kiến thức ngôn ngữ, ta có cây cú pháp của câu S như sau:
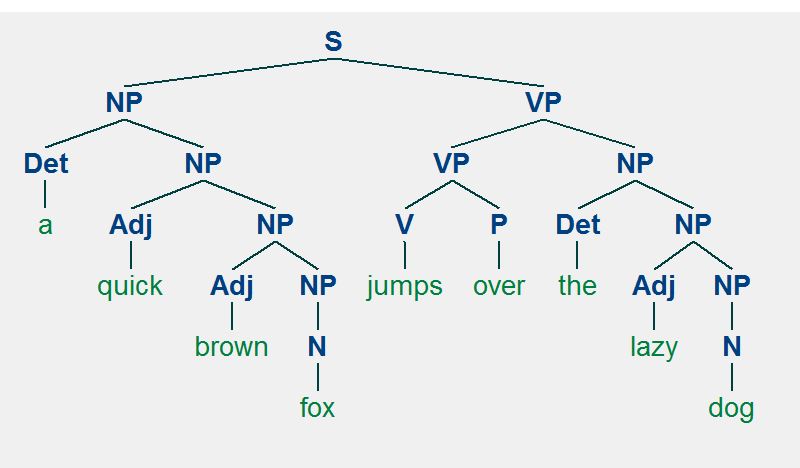
Dựa vào cây cú pháp biểu diễn như trên, ta dễ dàng rút trích ra chủ thể hành động là "the quick brown fox" trong đó "fox" là danh từ chính được bổ nghĩa bởi các tính từ "brown" và "quick"; và động từ chính của câu là "jumps". Cây cú pháp là cấu trúc cây với nút gốc là nút bắt đầu (__S__entence), từ nút gốc sẽ chia ra thành các nhánh là các thành phần chính của câu (Chủ ngữ - NP, Vị ngữ - VP). Các thành phần này lại tiếp tục đệ quy để sinh ra các nhánh là các thành phần khác chứa trong nó. Quá trình đệ quy sẽ dừng lại khi đến nút lá là các từ cụ thể với loại từ cụ thể và không thể phân chia được nữa. Từ cây cú pháp để đọc lại thành câu hoàn chỉnh chỉ cần duyệt cây từ trái sang phải thì ta sẽ lại có được văn bản hoàn chỉnh.
Nhập nhằn trong biểu diễn cú pháp
Một trong những vấn đề khó khăn trong xử lý ngôn ngữ tự nhiên chính là nhập nhằn, nhập nhằn trong cả hình thức lẫn ngữ nghĩa. Xét một ví dụ sau đây:
S = "I/Pro shot/V an/Det elephant/N in/P my/Det pajamas/N"
I shot an elephant in my pajamasPhân tích cú pháp ví dụ trên cho ta hai cây cú pháp sau:
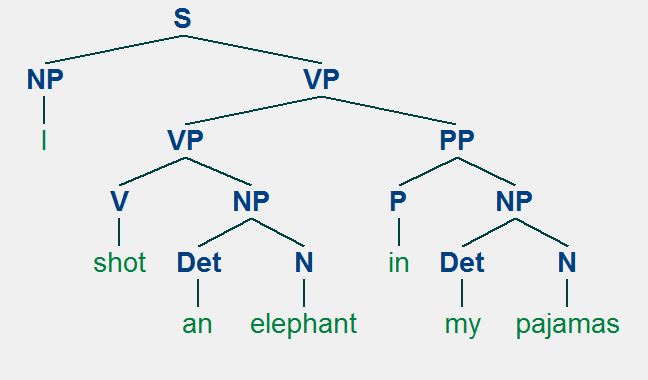
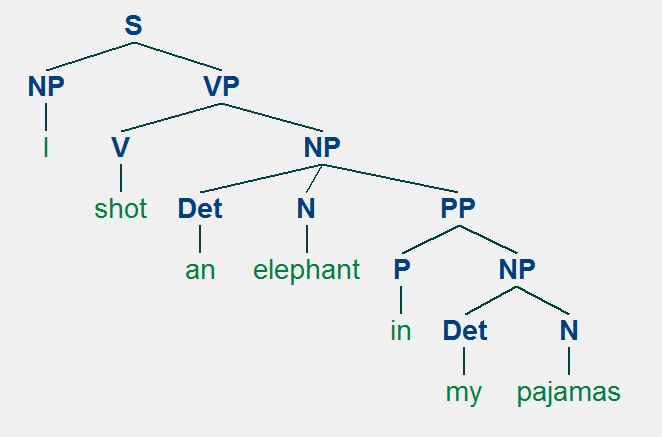
Tại sao lại có những hai cây cú pháp? Thực tế thì trong ngôn ngữ tự nhiên câu ví dụ trên có tới hai cách hiểu nên sẽ có tới hai cây cú pháp tương ứng. Cây cú pháp thứ nhất (bên trái) thể hiện ý nghĩa chủ ngữ là "I", thực hiện hành động là "shot", và trạng ngữ "in my pajamas" bổ nghĩa cho chủ ngữ "I" (Dịch ra tiếng Việt thì có thể hiểu là tôi bắn con voi trong lúc (tôi) bận bộ pajamas). Cây cú pháp thứ hai (bên phải) lại thể hiện ý nghĩa khác vì lúc này "in my pajamas" không bổ nghĩa cho "I" mà bổ nghĩa cho "the elephant" (Hay hiểu trong tiếng Việt là tôi bắn con voi trong lúc con voi đang ở trong bộ pajamas của tôi). Đối với con người việc phân định đâu là cấu trúc đúng rất đơn giản vì con người hiểu ngữ nghĩa của câu và có tri thức về ý nghĩa đó (con voi không thể ở trong bộ pajamas được hay ít nhất thì có vẻ việc "I" đi với "pajamas" có vẻ hợp lý hơn). Tuy nhiên, điều này lại trở nên khó khăn đối với máy tính vì máy tính không hiểu ngữ nghĩa của câu và lại càng không biết rằng con người đi với pajamas sẽ hợp lý hơn con voi. Đối với máy tính thì cả hai cách phân tích này đều đúng và chúng chỉ đơn thuần biết rằng câu trên cho ra hai cách phân tích cú pháp. Đôi khi sự nhập nhằn cũng khó phân định trong thực tế. Ví dụ với một câu tiếng Việt điển hình sử dụng phép chơi chữ "Hổ mang bò lên núi". Câu này có thể hiểu chủ ngữ là "Hổ mang", động từ là "bò" hoặc chủ ngữ là "Hổ", động từ là "mang" và cách hiểu nào trong thực tế đều cũng hợp lý. Để giải quyết nhập nhằn này ta lại phải xét thêm ngữ cảnh, đoạn văn, ... và như vậy lại càng khó cho máy tính. Một tin tốt là những câu như vậy không xuất hiện quá thường xuyên trong văn bản hàng ngày mà thường chỉ xuất hiện khi người dùng cố tình để tạo ra những cách chơi chữ trong ngôn ngữ. Chúng ta cũng không cần quá chú trọng giải quyết nhập nhằn vì chính chúng ta cũng không giải quyết được và hơn nữa việc máy tính phát hiện ra nhập nhằn đôi khi lại dẫn đến một cách hiểu mới cho văn bản mà ta chưa nhìn ra. Dù vậy, nhập nhằn vẫn là một vấn đề cần lưu ý khi phân tích cú pháp cho câu để tăng độ chính xác cho mô hình phân tích của chúng ta.
Văn phạm phi ngữ cảnh - Context Free Grammar (CFG)
Văn phạm của một ngôn ngữ chính là tập các quy tắc để nối ghép các từ trong ngôn ngữ đó. Để phân tích thành phần của câu chúng ta cần có văn phạm của ngôn ngữ tương ứng. Ví dụ: trong tiếng Việt tính từ đứng sau danh từ (quả táo đỏ), trong tiếng Anh tính từ lại đứng trước danh từ (red apple) nên không thể áp dụng văn phạm tiếng Anh để phân tích tiếng Việt. Văn phạm phi ngữ cảnh là văn phạm chỉ xét trên phạm vi dữ liệu văn bản, không xét yếu tố ngữ cảnh. Ví dụ câu "Kìa!" nếu xét trong một ngữ cảnh cụ thể thì nó có nghĩa nhưng nếu loại bỏ đi ngữ cảnh thì câu này trở nên vô nghĩa. Như vậy, văn phạm phi ngữ cảnh có thể hiểu là tập các luật dùng để hình thành câu mà không cần đến yếu tố ngữ cảnh. Để biểu diễn văn phạm phi ngữ cảnh, ta có thể biểu diễn theo cách sau:
S -> NP VP
NP -> det NP | Adj NP | pro | n
VP -> v NP | v NP PP | v PP
PP -> v NP
...
Trên là những luật của một văn phạm. Các luật đó có ý nghĩa: câu (S) có thể chia thành 2 thành phần NP (noun phrase) và VP (verb phrase); NP có thể tạo thành từ một mạo từ (det) kết hợp với một NP khác, hoặc từ một tính từ (Adj) kết hợp với một NP khác hoặc chỉ đơn giản NP là một danh từ (n) hoặc đại từ (pro); VP có thể bao gồm động từ (v) kết hợp với một NP, hoặc một PP, hoặc cả NP và PP. Ta có thể dùng văn phạm trên để phân tích một câu mà không cần đến ngữ cảnh. Lấy ví dụ cho câu "I eat a big turkey", ta có cây cú pháp như sau:
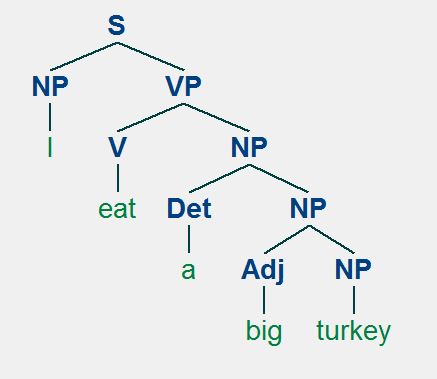
Trong cây cú pháp trên, ta thấy luật đã được áp dụng để chỉ ra rằng NP của câu là 'I' (pro), VP là 'eat a big turkey' bao gồm 'eat' (v) và một NP khác. Nếu chúng ta dùng luật trên để phân tích câu "Eat a I turkey big", mô hình phân tích có thể phát hiện câu trên là một câu sai vì không có luật thỏa câu "Eat a I turkey big". Mỗi ngôn ngữ đều có một văn phạm và nếu ta xây dựng được bộ văn phạm đầy đủ của ngôn ngữ đó thì ta có thể phân tích cú pháp văn phạm của một câu bất kỳ thuộc ngôn ngữ đó (không phụ thuộc vào ngữ cảnh). Trong văn phạm phi ngữ cảnh, các thành phần của câu có thể chia là hai nhóm chính: Terminal (thành phần kết thúc) và Non-terminal (thành phần chưa kết thúc). Các thành phần kết thúc là những thành phần mà không thể phân giải ra nữa và ngược lại, các thành phần kết thúc là các thành phần vẫn có thể tiếp tục phân giải. Như vậy khi phân tích câu, kết quả cuối cùng của quá trình phân tích (tức nút lá của cây cú pháp) chỉ bao gồm các thành phần kết thúc, cũng chính là các nhãn từ loại của câu. Các thành phần kết thúc này (non-terminal) là chìa khóa quan trọng cho các mô hình phân tích vì vậy đi kèm với bộ luật văn phạm chúng ta cũng cần đánh nhãn từ loại cho dữ liệu.
Một số mô hình phân tích văn phạm dựa trên CFG
Mô hình phân tích Top-down
Ý tưởng cơ bản của mô hình này chính là dựa trên luật sinh ra một mô hình cây rồi đối sánh với văn bản đầu vào. Nói đơn giản chính là đi từ luật đến văn bản. Recursive Descent Parser (thuật toán duyệt xuống có đệ quy) là một trong những thuật toán điển hình cho mô hình này. Thuật toán đi từ nút gốc S và duyệt qua tập luật để tìm những luật có thể mở rộng cây từ nút S và thêm các thành phần được sinh ra từ S (vd như NP, VP) vào cây. Sau đó đi sang nhánh trái và tiếp tục mở rộng cây (vd: NP sẽ thêm vào cây nút Det, N) cho đến khi đến một nút là thành phần kết thúc thì sẽ so khớp nhãn từ loại này với từ loại của từ tương ứng trong câu (mô hình duyệt cây đi từ trái sang phải nên từ tương ứng cũng theo thứ tự trái sang phải - phù hợp cách đọc thông thường của con người). Nếu khớp thì tiếp tục sinh cây từ luật còn nếu không khớp thì loại bỏ cây đó. Sau quá trình duyệt hết một cây (kể cả phân tích thành công hoặc hủy cây giữa chừng) mô hình sẽ đệ quy hay truy hồi ngược lại để thử áp dụng các luật khác và sinh cây khác. Việc truy hồi như vậy là để cho trường hợp một câu có thể có hai cách phân tích như nói ở trên. Hạn chế của mô hình top-down là không bám sát văn phạm mà sính cây trước. Thứ tự chọn luật sinh cây có thể ảnh hưởng đến việc có phân tích được cú pháp hoàn chỉnh hay không, đồng thời phải duyệt qua các cấu trúc thừa. Hơn nữa trong nhiều ngôn ngữ, luật văn phạm có mang tính đệ quy (vd NP -> det NP) sẽ dẫn đến việc sinh cây rơi vào các nhánh có độ sâu vô hạn.
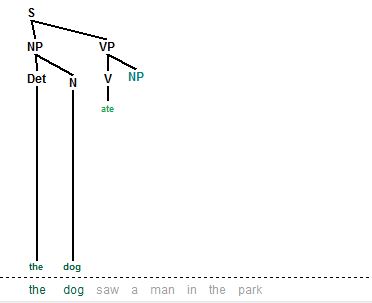
Mô hình phân tích Bottom-up
Tránh những sai lầm của mô hình top-down, mô hình bottom-up có hướng tiếp cận ngược lại: đi từ văn bản đến luật. Điển hình cho mô hình này là thuật toán Shift-Reduce Parser (thuật toán dịch chuyển và gom cụm). Thuật toán bắt đầu với văn bản đầu vào, lần lượt dịch chuyển các từ với nhãn từ loại của nó, cũng chính là các thành phần kết thúc (terminal), vào hàng đợi. Nếu tồn tại cách gộp các thành phần hiện có trong hàng đợi thành một thành phần chưa kết thúc (non-terminal) dựa theo luật thì gom lại và thay thế thành non-terminal đó. Tóm tắt lại là lần lượt từng từ sẽ được bỏ vào hàng đợi và kết hợp với nhau thành một thành phần lớn hơn. Việc gộp sẽ được lặp cho đến khi chỉ còn lại thành phần cao nhất là S (nút của cây cú pháp). Vd: câu "The man saw a dog" thì từ "The" sẽ được đưa vào hàng đợi trước, sau đó đến từ "man", lúc này ta có luật "NP -> det n" phù hợp nên hai từ "The", "man" sẽ được gộp thành một thành phần NP. Các từ "saw", "a", "dog" cứ thế tiếp tục vào hàng đợi và gộp thành nhóm.


Cách tiếp cận này giúp câu phân tích sát với văn bản, không phải duyệt qua các cấu trúc thừa đồng thời tránh lặp vô hạn với các luật đệ quy. Tuy nhiên, việc gom nhóm sớm có thể dẫn đến việc tạo thành các thành phần mới quá sớm và không phù hợp với cách phân tích thật trong khi đáng lẽ phải chờ một hay hai từ nữa để gom nhóm (vd: có hai luật VP -> v NP và VP -> v NP PP thì chưa chờ PP vào mô hình gộp ngay v NP thành VP khiến cho cả cụm "saw a dog in the park" vốn là một VP bị cắt thành "see the dog" là VP và "in the park" bị loại bỏ).
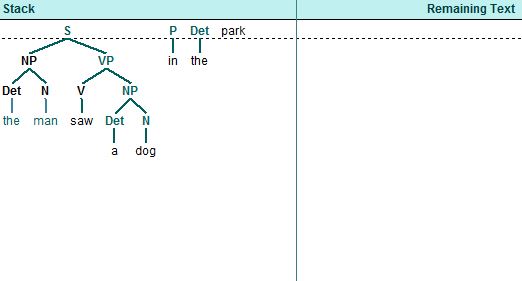
Việc phạm sai lầm như vậy đôi khi còn dẫn đến những nhánh cụt (dead end) và khiến cho không phân tích được dù cho câu hoàn toàn đúng theo luật. Cho nên cũng phải cân nhắc khi lựa chọn mô hình hoặc kết hợp cả top-down và bottom-up để tăng độ chính xác.
Bài viết tham khảo từ các nguồn