Tổng quan
Mạng Nơ-ron tự tổ chức (seft-organizing map), hay còn gọi là mạng Kohonen là một loại mạng nơ-ron nhân tạo được huấn luyện thông qua phương pháp học không giám sát. Khác với các mô hình mạng nơ-ron truyền thẳng hay mạng nơ-ron tích chập, mạng kohonen sử dụng cách học cạnh tranh (competitive learing) thay vì phương pháp sửa lỗi (error correction). Mô hình này được đề xuất bởi Teuvo Kohonen vào những năm 1980 dựa trên một phần cách thức mà các tín hiệu được xử lý trong não bộ. Cũng giống với các mô hình nơ-ron khác, mạng Kohonen cũng cần trải qua quá trình huấn luyện. Tuy nhiên, như đã đề cập, phương pháp và ý tưởng của mạng Kohonen có nhiều sự khác biệt so với các mô hình mạng nơ-ron học theo phương pháp học có giám sát. Mạng Kohonen với phương pháp học không giám sát được sử dụng hiệu quả trong các bài toán gom nhóm (clustering). Có thể nói mô hình này gần giống với phương pháp gom nhóm K-mean hơn là các mạng nơ-ron khác.
Huấn luyện cho mạng Kohonen
Kiến trúc của một mạng Kohonen đơn giản bao gồm 2 lớp: lớp nhập và lớp xuất. Lớp nhập bao gồm các nút ứng với các đặc trưng của dữ liệu đầu vào. Nếu dữ liệu đầu vào là một vector có m đặc trưng thì lớp nhập sẽ có m nút tương ứng. Lớp xuất đại diện cho số lượng nhóm cần gom nhóm. Nếu bài toán yêu cầu phân loại các đối tượng thành 10 nhóm thì lớp xuất sẽ gồm 10 nút.
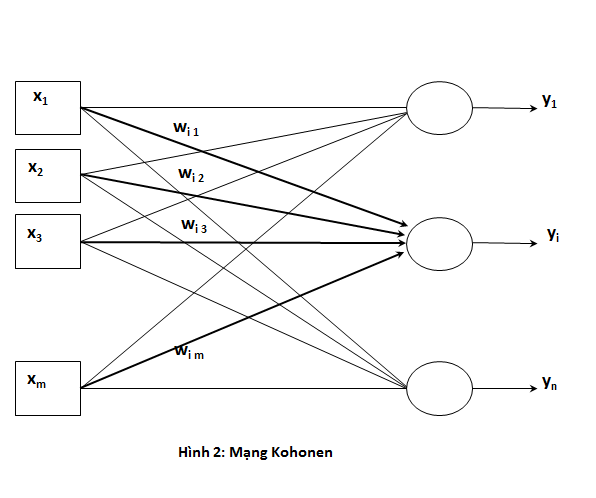
Các nút ở lớp nhập và lớp xuất được liên kết đầy đủ với nhau thông qua các trọng số w. Như vậy một nơ-ron ở đầu ra sẽ có m trọng số nối đến nó tương ứng với m đặc trưng của dữ liệu đầu vào. Các trọng số này đóng vai trò đại diện cho nhóm tương ứng với nơ-ron ở lớp xuất và có nhiệm vụ tính toán và phân loại đối tượng đầu vào sẽ vào lớp nào trong các nút ở đầu ra. Các giá trị trọng số w sẽ được khởi gán ngẫu nhiên khi khởi tạo mô hình.
Quá trình huấn luyện
Với một mạng Kohonen có m đặc trưng đầu vào cần gom nhóm thành n nhóm đầu ra, ta gọi wij là trọng số nối giữa đầu vào thứ j và đầu ra thứ i. Một mẫu dữ liệu vào sẽ gồm m đặc trưng xj (j từ 1 đến m). Quá trình huấn luyện cho mạng kohonen như sau:
- Lấy một mẫu dữ liệu học đưa vào mô hình.
- Với mỗi nút tại lớp ra, tính khoảng cách Euclide (hoặc một độ đo thích hợp khác) giữa vector đặc trưng đầu vào và vector trọng số nối với nut đó. Lấy nút có giá trị tính được nhỏ nhất, gọi là best matching unit.
- Cập nhật trọng số gắn với nút đó: . Với là hệ số học, thể hiện cho mức độ cập nhật W sau mỗi lần lặp.
- Tiến hành lặp lại các bước trên cho mẫu dữ liệu mới cho đến khi đạt một số lần lặp nhất định. Ta thấy rằng cách thức hoạt động của mô hình rất giống với thuật toán k-mean. Cứ mỗi mẫu dữ liệu đưa vào thì giá trị trọng số của nút gần nó nhất (best matching unit) sẽ được cập nhật lại theo kiểu kéo dần về phía của mẫu dữ liệu trong không gian biểu diễn. Như vậy sau nhiều mẫu dữ liệu được dùng để học thì giá trị trọng số của một nút đầu ra chính là đặc trưng trung bình của nút đó. Nếu một mẫu dữ liều mới cần phân loại được đưa vào, khoảng cách từ nó đến giá trị trung bình nào nhỏ nhất thì nó sẽ có nhiều khả năng thuộc nhóm đó.
Ví dụ
Xét một tập dữ liệu gồm 8 mẫu (1,1), (1,2), (2,1), (2,2), (4,4), (4,5), (5,4), (5,5) như sau:
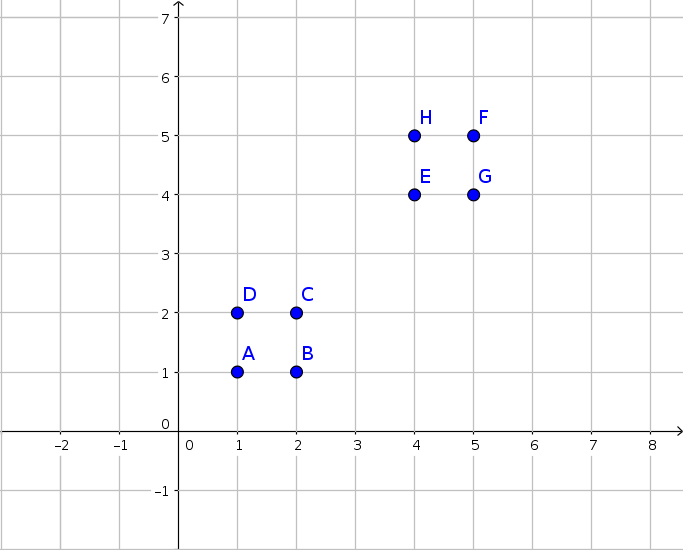
Yêu cầu đặt ra là sử dụng mạng Kohonen để phân tập dữ liệu này thành 2 nhóm. Truớc tiên ta cần xây dựng kiến trúc cho mạng Kohonen. Tập dữ liệu gồm hai loại đặc trưng là tọa độ x, y nên lớp nhập sẽ gồm 2 nút nhập. Ta cần phân tập dữ liệu thành 2 nhóm nên lớp ra cần có 2 nút. Như vậy ma trận trọng số giữa lớp nhập và lớp xuất là một ma trận 2×2. Giả sử ta khởi tạo bộ trọng số nối với đầu ra 1 là và , bộ trọng số nối với đầu ra 2 là và . Duyệt qua mẫu đầu tiên (1,1), ta có khoảng cách Euclide giữa mẫu dử liệu và từng cặp trọng số lần luợt là và . Như vậy ta cập nhật lại bộ trọng số gắn với nút 1 và . Nếu thể hiện bộ trọng số này như một điểm trên đồ thị thì ta có thể thấy rằng điểm này đã đuợc cập nhật để di chuyển dần về phía nhóm dữ liệu 1. Duyệt tiếp điểm số 2 (2,2), ta lại tiếp tục tính d1 = 0.5 và d2 = 2 và tiếp tục cập nhật cho bộ trọng số gần nó hơn: và . Duyệt điểm tiếp theo (4,4), ta tính d1 = 3.01, d2 = 2 và cập nhật trọng số gắn với nút 2 và . Một lần nữa, ta dễ dàng nhận thấy rằng bộ trọng số 2 đã đuợc kéo về gần với nhóm dữ liệu 2 hơn. Tiếp tục duyệt qua các mẫu dữ liệu còn lại, bộ trọng số sẽ liên tục đuợc cập nhật và đuợc đưa về vị trí trung bình của các nhóm dữ liệu sau một số lượng lần lặp đủ lớn. Như vậy mạng Kohonen đã gom nhóm thành công.
Mở rộng không gian
Mạng Kohonen hai chiều Đôi khi dữ liệu đầu vào là những đặc trưng sắp xếp theo không gian 2 chiều hoặc các nút lớp ra có thể được sắp xếp theo không gian hai chiều.
kiến trúc 2 chiều của mạng kohonen
Trong những kiến trúc mạng lớn, việc cập nhật trong số không chỉ xảy ra ở nơ-ron tốt nhất (best matching unit) mà các nơ-ron trong vùng lân cận cũng có thể được cập nhật. Vùng lân cận ở đây có thể tùy theo bài toán mà có thể là vùng 4 nơ-ron hoặc 8 nơ-ron xung quanh (trong kiến trúc hình chữ nhật) hoặc 6 nơ-ron xung quanh (trong kiến trúc hình lục giác). Việc cập nhật như vậy sẽ khiến những nơ-ron gần nhau sẽ biểu diễn những nhóm có độ tương đồng cao.
Không gian đặc trưng
Đôi khi đặc trưng ta rút trích ra có sự phân bố hỗn loạn, những đối tượng đáng lý ra phải thuộc một nhóm thì lại nằm rải rác trong không gian dữ liệu. Do đó, chúng cần chọn một độ đo tương quan cho phù hợp để các đối tượng trong cùng một nhóm phải có khoảng cách gần nhau. Hoặc ta có thể dùng các kernel hay các phương pháp ánh xạ và biến đổi không gian như PCA, LDA để ánh xạ không gian dữ liệu hỗn loạn thành không gian dữ liệu dễ phân tách và gom nhóm hơn.
Gia tăng đầu ra
Xét trong trường hợp mô hình nhận vào một mẩu dữ liệu không thuộc về một bất kỷ lớp nào trong các lớp cho trước. Tuy nhiên dù vậy mô hình vẫn sẽ xếp nó vào nhóm nào có khoảng cách, hay độ tương đồng gần với nó nhất. Một trong những cách xử lý vấn đề này chính là đặt ngưỡng cho giá trị khoảng cách nhỏ nhất. Nếu một mẫu có độ tương đồng tốt nhất với một nhóm nào đó nhưng độ tương đồng này vẫn còn cao hơn ngưỡng, hay khoảng cách từ nó đến tất cả các nhóm đều không đủ nhỏ thì ta có lý do để tin rằng nó là một nhóm mới. Khi phát hiện một nhóm mới ta sẽ hình thành một nút mới tại đầu ra đại diện cho nơ-ron đó với giá trị trọng số chính là giá trị đặc trưng của mẫu vừa tìm được. Với cách này, mô hình có thể dễ dàng mở rộng hơn cho nhiều lớp đối tượng khác nhau.
Khởi tạo trọng số
Khởi tạo trọng số là vấn đề khá quan trọng trong mô hình kohonen. Nếu các giá trị trọng số ban đầu quá xa so với giá trị hội tụ của chúng thì mạng sẽ phải huấn luyện với chi phí thời gian cao. Đối với các bộ dữ liệu có đặc tính phân bố khá tập trung (xác xuất một mẫu dữ liệu có giá trị gần giá trị trung vị cao) thì ta có thể chọn một mẫu dữ liệu và lấy giá trị đặc trưng của nó làm giá trị trọng số cho nút đầu ra.
Xây dựng mạng Kohonen trên tập MNIST
Dữ liệu và siêu tham số
Việc đầu tiên, chúng ta cần chuẩn bị dữ liệu. Chúng ta có thể sử dụng tập dữ liệu MNIST được cung cấp sẵn trong thư viện tensorflow. Một mẫu dữ liệu trong tập MNIST có số chiều là 784 ứng với một ảnh 28x28. Ta sẽ chuyển các mẫu dữ liệu này về 1x784 chiều để dễ trong việc tính toán.from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
train = mnist.train.images.reshape(data.train.images.shape[0], 1, 784)
Tiếp theo chúng ta cần xác định các siêu tham số của mô hình. Có 2 siêu tham số quan trọng là hệ số học và số lượng nodes đầu ra của mô hình hay số nhóm mà chúng ta cần gom nhóm. Đôí với tập MNIST thì ta có 10 nhóm ứng với 10 ký số khác nhau. Tuy nhiên, số lượng và mật độ phân bố của các mẫu dữ liệu rất đa dạng, rất khó để gom nhóm một cách chính xác nếu chỉ phân ra 10 nhóm. Thay vào đó ta có thể thêm các nhóm phụ như số 5 nghiên sang trái, số 5 nghiêng sang phải, ... để tăng tính hiệu quả trong việc gom nhóm. Ở đây, ta sẽ thử chọn gom thành 100 nhóm khác nhau với hệ số học .
alpha = 0.1 batch_size = 100 output_nodes = 100
Hàm lân cận (neighborhood)
Khi cập nhật trọng số của mô hình, ngoài trọng số có khoảng cách gần nhất với giá trị dữ liệu đang xét, ta cũng cần cập nhật những trọng số nằm trong vùng lân cận. Định nghĩa của lân cận ở đây tùy thuộc vào mỗi người, có thể là 4 ô xung quanh hoặc 8 ô xung quanh.def neighborhood(i):
result = [i]
x, y = i // 10, i % 10
if (x - 1 >= 0):
result.append(10*(x - 1) + y)
if (y + 1 < 10):
result.append(10*x + y + 1)
if (x + 1 < 10):
result.append(10*(x + 1) + y)
if (y - 1 >= 0):
result.append(10*x + y - 1)
return result
Xây dựng và huấn luyện mô hình
Trước tiên ta khởi tạo trong số của mô hình gồm 10x10 trọng số với 784 chiều ứng với 100 điểm trọng tâm. Để đơn giản thay vì tạo mảng 2 chiều 10x10, ta tạo môt mảng một chiều gồm 100 phần tử với 784 chiều. Hàm lân cận cũng được viết để phù hợp với cách khởi tạo này.W = np.random.rand(output_nodes,784)Ta tính khoảng cách giữa các trọng tâm với các điểm dữ liệu và tìm ta trọng tâm có khoảng cách nhỏ nhất.
data_batch = train[i*batch_size:i*batch_size + batch_size] distance = np.sum(np.square(data_batch - W), axis=2) min_nodes = np.argmin(distance, axis=1)Tiếp đến, ta cập nhật trọng số được chọn và các trọng số lân cận.
for j in range(batch_size):
neighbor = neighborhood(min_nodes[j])
for index in neighbor:
W[index] += alpha*(data_batch[j].reshape(784) -W[index])
Lặp lại nhiều lần quá trình huấn luyện.
for epoch in range(5):
for i in range(500):
data_batch = train[i*batch_size:i*batch_size + batch_size]
distance = np.sum(np.square(data_batch - W), axis=2)
min_nodes = np.argmin(distance, axis=1)
for j in range(batch_size):
neighbor = neighborhood(min_nodes[j])
for index in neighbor:
W[index] += alpha*(data_batch[j].reshape(784) -W[index])
Kết quả huấn luyện
Hàm chuyển đổi bộ trong số về thành một ma trận hình ảnh để hiển thị kết quả huấn luyện.def make_image(W):
result = np.zeros((W.shape[0] * 28, W.shape[1] * 28))
for i in range(W.shape[0]):
for j in range(W.shape[1]):
for m in range(28):
for n in range(28):
result[i*28 + m][j*28 + n] = W[i][j][m][n]
return result
Kết quả trước và sau khi huấn luyện.
 -
- 
Có thể thấy kết quả hội tụ về khá tốt dù chỉ với 5 epoch. Kết giá trị trọng số đã hội tụ về các điểm trung tâm của các nhóm và thể hiện được đặc trưng của nhóm.
Áp dụng cho bài toán nhận dạng ký số viết tay
Mặc dù mô hình Self Organising Map là môt mô hình gom nhóm nhưng cũng có thể áp dụng vào cho bài toán nhận dạng. Sau quá trình gom nhóm ta đã có được giá trị trung tâm đại diện cho từng nhóm. Từ đây ta có thể áp dụng Nearest Neighbor để tiến hành phân lớp. Khi một mẫu dữ liệu mới vào, ta sẽ so sánh nó với các giá trị đại diện của nhóm. Những nhóm gần với giá trị mẫu dữ liệu nhất sẽ quyết định nhãn của mẫu dữ liệu đó. Việc chọn số lượng nhóm sẽ ảnh hưởng tính hiệu quả của việc gom nhóm nên từ đó cũng ảnh hưởng đến hiệu quả của việc phân lớp. Nếu chỉ phân thành 10 nhóm, độ chính xác có thể chỉ được 50% nhưng nếu phân thành 100 nhóm, độ chính xác có thể lên đến 80%.
Bài viết tham khảo từ các nguồn
https://en.wikipedia.org/wiki/Self-organizing_map